Java读取Excel数据,解析文本并格式化输出
Java读取Excel数据,解析文本并格式化输出
Java读取Excel数据,解析文本并格式化输出
下图是excel文件的路径和文件名

下图是excel文件里面的内容
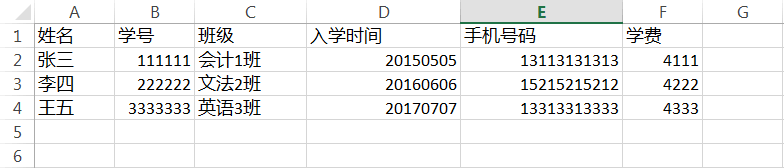
下面是Java读取Excel数据的代码
package excel_driver;import java.util.List;import java.io.FileInputStream;import java.io.InputStream;import java.util.ArrayList;import org.apache.poi.xssf.usermodel.XSSFCell;import org.apache.poi.xssf.usermodel.XSSFRow;import org.apache.poi.xssf.usermodel.XSSFSheet;import org.apache.poi.xssf.usermodel.XSSFWorkbook;public class excel_driver { private static List > readXlsx(String path) throws Exception { InputStream is = new FileInputStream(path); XSSFWorkbook xssfWorkbook = new XSSFWorkbook(is); List > result =new ArrayList >(); //循环每一页,并处理当前循环页 //for(XSSFSheet xssfSheet : xssfWorkbook){ for(int numSheet=0; numSheet < xssfWorkbook.getNumberOfSheets(); numSheet++){ XSSFSheet xssfSheet = xssfWorkbook.getSheetAt(numSheet); if (xssfSheet==null) continue; //处理当前页,循环读取每一行 for(int rowNum=1; rowNum<=xssfSheet.getLastRowNum();rowNum++){ XSSFRow xssfRow = xssfSheet.getRow(rowNum); int minColIx = xssfRow.getFirstCellNum(); int maxColIx = xssfRow.getLastCellNum(); List rowList = new ArrayList ();// System.out.println("\t"); //遍历该行获取处理每个cell元素 for(int colIx=minColIx;colIx > a = readXlsx("C:\\Users\\chenjia\\Desktop\\excel_driver.xlsx");// for (int i = 0; i < a.size(); i++) {// System.out.println(a.[i]);// } for(List list:a) { System.out.println(list); } System.out.println(a); System.out.println(a.size());// System.out.println(a.[1]); } }
package excel_driver;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.xssf.usermodel.XSSFCell;public class getString { public static String getStringVal (XSSFCell cell){ switch (cell.getCellType()) { case Cell.CELL_TYPE_BOOLEAN: return cell.getBooleanCellValue() ? "TRUE" : "FALSE"; case Cell.CELL_TYPE_FORMULA://公式格式 return cell.getCellFormula(); case Cell.CELL_TYPE_NUMERIC://数字格式 cell.setCellType(Cell.CELL_TYPE_STRING); return cell.getStringCellValue(); case Cell.CELL_TYPE_STRING: return cell.getStringCellValue(); default: return "????"; } }} 运行结果是:
[张三, 111111, 会计1班, 20150505, 13113131313, 4111][李四, 222222, 文法2班, 20160606, 15215215212, 4222][王五, 3333333, 英语3班, 20170707, 13313313333, 4333][[张三, 111111, 会计1班, 20150505, 13113131313, 4111], [李四, 222222, 文法2班, 20160606, 15215215212, 4222], [王五, 3333333, 英语3班, 20170707, 13313313333, 4333]]3
下面是原文章:
相关技术
使用的POI解析Excel需要使用的jar包
注(使用的maven.我就添加了右边的两个依赖就可以了)
分析
解析Excel首先就要解析Excel的结构.然后用面向对象的思想分析一下
这是一个excel文件.下面我们就来分析一下如果让你写这个poi框架,那么你会怎么设计. 1. 首先要有一个对象表示这整个Excel文件. 2. 可是这个excel文件中有好多页.Sheet1, Sheet2等等,所以我们还需要一个对象表示页. 3. 在页中,有行,所以还需要一个对象表示行. 4. 在行中,最后细分到格cell. 5. 格cell中数据还有好多类型.有字符串,数字,时间等等.
POI中的对象与excel对象的对应
excel文件就有多种类型了.后缀有 xls 与 xlsx
所以对于不同类型的文件,就需要使用不同的poi中的对象了. 1. 如果你要解析的是xls文件
从代码不难发现,这里的处理逻辑是 1>. 先用inputstream获取excel文件的io流 2>. 然后创建一个内存中的excel文件HSSFWorkbook类型对象.这个对象表示了整个excel文件. 3>. 对这个excel文件的每页做循环处理 4>. 对每页中的每行做循环处理. 5>. 对每行中的每个单元格做做处理,获取这个单元格的值. 6>. 把这行的结果添加到一个List数组中. 7>. 把每行的结果添加到最后的总结果中. 8>. 解析完以后就获取了一个List< List < String > > 类型的对象了. 2. 如果你要处理xlsx类型的文件则
和上面一样,我就不说了.
存在的问题
其实有时候我们希望得到的数据就是excel中的数据,可是最后发现结果不理想
如果你的excel中的数据是数字,你会发现中对应的变成了科学计数法的. 所以在获取值的时候就要做一些特殊处理. 这样就能保证获取的值是我想要的值. 网上的做法是对于数值类型的数据格式化,获取自己想要的结果. 其实也没有那么麻烦.我在做的时候突然想到了一种处理解决方案.供参考 我们看一下poi中对于的toString()方法该方法是poi的方法,从源码中我们可以发现,该处理流程是 1. 获取单元格的类型 2. 根据类型格式化数据并输出.这不一下子就造成了很多不是我们想要的. 所以我们就要改造一下这个方法例如这样
我的做法是这样的 1. 对于不熟悉的类型,或者为空则返回”” 控制串. 2.如果是数字,则修改单元格类型为String,然后返回String.这样就保证数字不被格式化了. 3. 虽然不知道这么做有什么后果,可是成功了.
